What are the top AI models? Here is the consensus on top models for February 2026 as well as new releases.
- Consensus zeitgeist read: 5.3 Codex is now the most powerful coding model, and has more generous limits than Claude Code.
- Users are finding they hit limits in Claude Opus 4.6 much faster than GPT-5.2 (even w/Thinking)
February 2026 Releases:
- OpenAI Release February 5, 2026: GPT-5.3-Codex – OpenAI’s new powerful model for Codex. Developers are loving this and switching from Claude Code.
- OpenAI Release February 12, 2026: GPT-5.3-Codex-Spark – 1,000 tokens per second. Game is changed. Move is on Claude Code to catch up.
- Anthropic Release February 6, 2026: Claude Opus 4.6 released to much fanfare with a 1m token context window in beta.
- Google Gemini Release Feb 12, 2026: Gemini 3 Deep Think – specialized reasoning mode – pushing the frontier and establishing new benchmarks.
- xAI Grok is stuck with 4.1: Co-founders are leaving, xAI opening Seattle office. Don’t bet against Elon.
- xAI acquired by SpaceX in trillion dollar+ combined valuation. X employees ecstatic at SpaceX stock conversion.
New Year 2026 AI Model Rankings
January 2026 Highlights & Releases:
- ChatGPT 5.2 is the most popular and powerful general-purpose model with generous limits
- Claude Opus 4.5 in Claude Code is seen as another creature, as the penultimate AI coding experience. Some are saying that “coding is solved”
- Claude is rolling out more and more Claude Code improvements with Skills being loved by all
- ClaudeBot is going to the stratosphere. Mac Minis are flying off the shelf for the iMessage capabilities. Things may never be the same.
- xAI remains a favorite for being more uncensored. Grokipedia is a fascinating experiment and a challenger to Wikipedia, powered by Grok. xAI is the dark horse to win it all.
- Some say that Google’s Gemini is inevitable and will win it all based on Google’s distribution.
Arc Prize 2026 Ranking Update
There are a lot of different ranking systems, but the Arc Prize is a great one to start with as a definitive source of LLM leaderboard rankings. See our post on AI ranking factors for more intel.
As of January 6, 2026, these are the top-ranked LLM models:
| Rank | AI System | Author | System Type | ARC-AGI-1 | ARC-AGI-2 | Cost/Task |
| 1 | Human Panel | Human | N/A | 98.00% | 100.00% | $17.00 |
| 2 | GPT-5.2 Pro (High) | OpenAI | CoT | 85.70% | 54.20% | $15.72 |
| 3 | Gemini 3 Pro (Refine.) | Poetiq | Refinement | N/A | 54.00% | $30.57 |
| 4 | GPT-5.2 (X-High) | OpenAI | CoT | 86.20% | 52.90% | $1.90 |
| 5 | Gemini 3 Deep Think (Preview) ² | CoT | 87.50% | 45.10% | $77.16 | |
| 6 | GPT-5.2 (High) | OpenAI | CoT | 78.70% | 43.30% | $1.39 |
| 7 | GPT-5.2 Pro (Medium) | OpenAI | CoT | 81.20% | 38.50% | $8.99 |
| 8 | Opus 4.5 (Thinking, 64K) | Anthropic | CoT | 80.00% | 37.60% | $2.40 |
| 9 | Gemini 3 Flash Preview (High) | CoT | 84.70% | 33.60% | $0.23 | |
| 10 | Gemini 3 Pro | CoT | 75.00% | 31.10% | $0.81 |
The ARC Prize is a solid ranking, however there are some downsides:
- Does not measure the speed of these models
- Does not rank by a combination of score, speed, and cost
- Does not show the limitations of requests for each of these models
For both personal and business users, these three factors are crucial for understanding their role within business process pipelines.
For example, GPT-5.2 (X-High) is not a model widely accessible without extra configuration. This Reddit user complained:
“Unless you have 10-30 minutes for each task you give it, this model is useless.
I would rather use less smart model like Gemini 3 pro that can do things like 10 times faster.
The only use case i can think of either doing things on background. Like walking outside or going to the gym and typing what the model should do, and then when you come back you look at the results.”
Orca’s 2025 AI Models Report
A new report by Orca ranked the “10 most popular AI models of 2025 based on analysis of billions of cloud assets by the Orca Research Pod.”
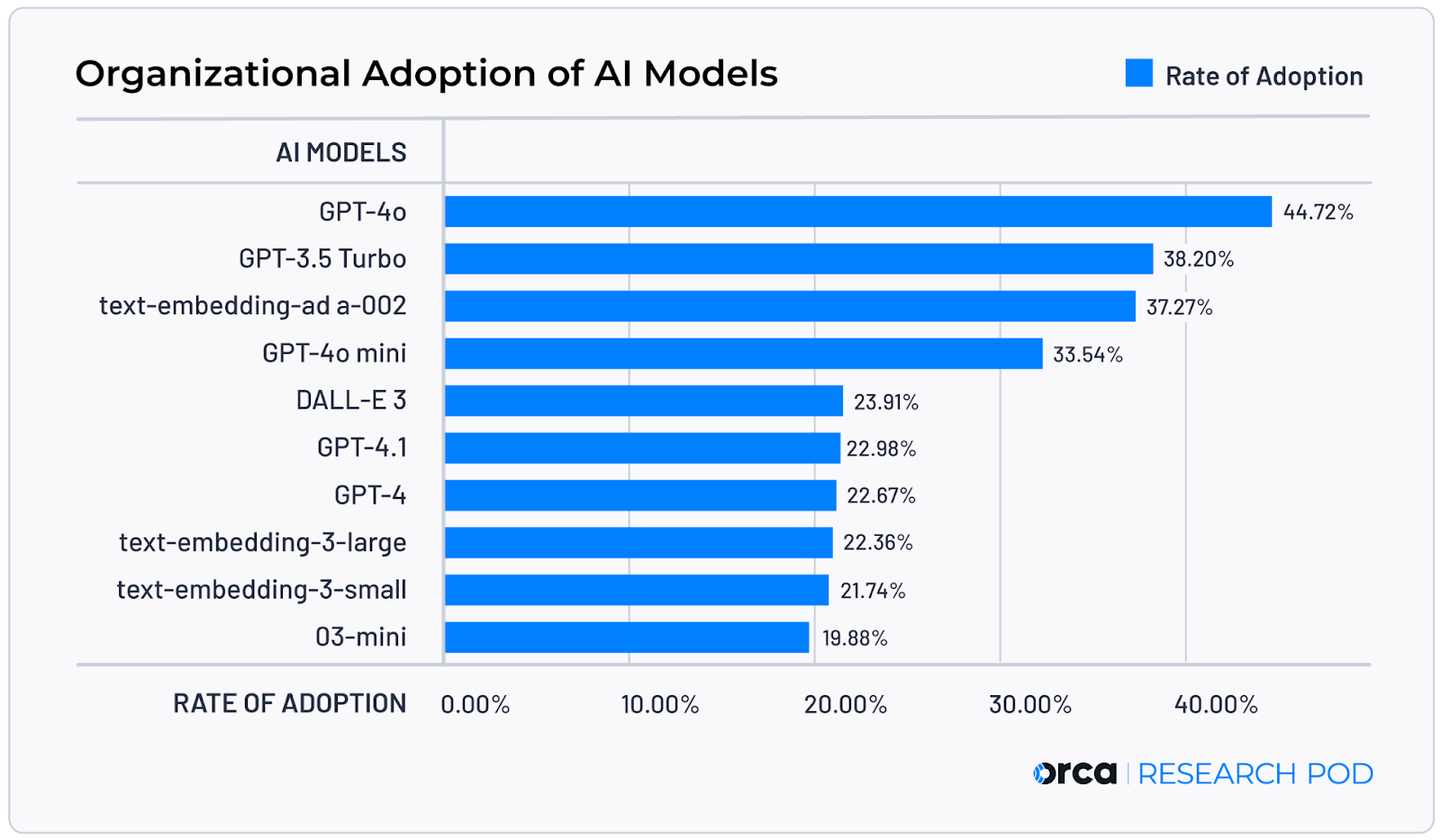
One issue I may have with the report is any lack of GPT-5 mention or adoption. Perhaps enterprises are reluctant to implement the latest model in production, but given that it was released August 7, 2025 I would have expected to see it rank somewhere on the list. It’s possible that it was #11, and just didn’t make the top 10.
Opinions & Predictions for the Best AI Models by the End of 2026
Editorial opinions by Joe Robison, founder of Green Flag Digital, for 2026:
- We will see a race to real-time virtual personal assistants.
- OpenAI will retain the crown for the best general-purpose AI at wide distribution. Others like Claude Code and
- OpenAI will become a mega-search crawler on their own, as large as Google’s crawler using different techniques.
- OpenAI will purchase crawling, indexing, ranking companies, including Exa.ai.
- Apple or Google will buy Perplexity.
- Lovable will be acquired in a huge deal by Google or Anthropic.
- Replit will be on the IPO path for 2027.
- The AI model companies will end up like the big cloud computing companies, carving up 4-5 distinct domains
- Prediction markets will roar between 2026-2030 and grow massively. 2026 will be an explosive year of growth.
- AI models will continue to be embedded in the real world more and more, as seen recently in drive-thru order windows such as Carl’s Jr.
Polymarket AI model predictions for 2026:
Polymarket, Kalshi, and other prediction markets are emerging as massive “truth machines” with potentially transformative, Minority-Report meets Jason Borne-esque ramifications for 2026-2030.
As it stands on Monday Jan 5, 2026 at 6:18pm PST, Kalshi gamblers predict that Google will have the best AI model at the end of January 2026. See this bet here: What will be the top AI model this month?
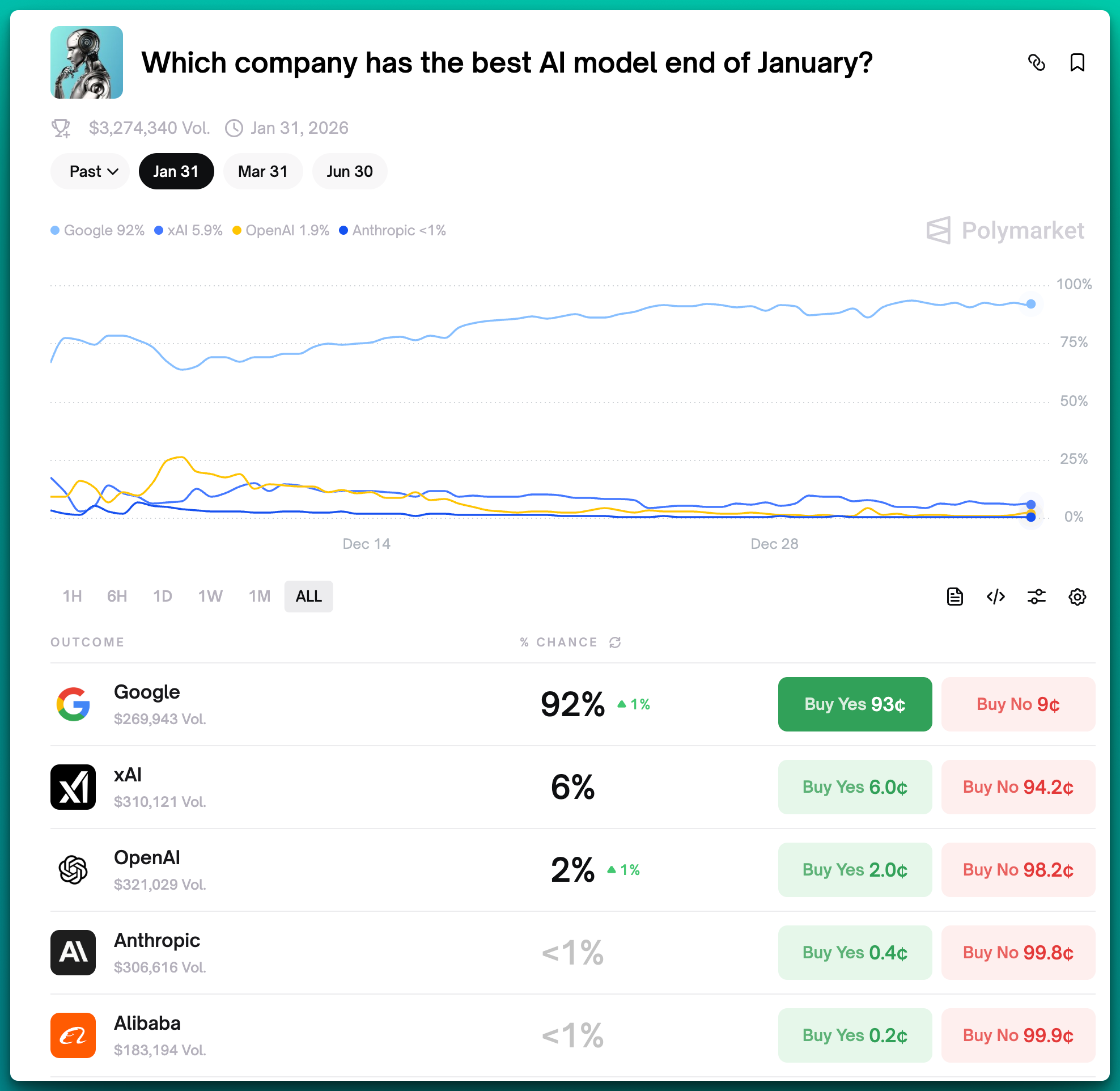
Are prediction markets reliable for predicting the best AI models? They’re not perfect. However, they do incentivize betters to reveal the truth with their stakes. If you feel strongly about a prediction – such as what the best model is – you can place your bet and earn a monetary reward.
Just like sports betting, it’s a gamble. But they may point us in the right direction and show what the consensus view is.
You can then decide to bet with the consensus, or against it. And the truth will be revealed in the fullness of time.
And right now, the consensus is that Google will have the best model by January 31, 2026. Personally, I don’t buy it. I think OpenAI is cooking up the next GPT model – they have to. They’re likely releasing GPT 5.3
Previous AI Model Rankings – and Changes over Time
October 26, 2025 Rankings
Just eyballing it, but GPT-5 Pro is the current top AI model in production, only beaten by custom AIs and a human panel.
Grok 4 (Thinking) is the #2 production model, with a very solid cost/task of $2.17 compared to GPT-5 Pro’s $7.14 a task for pretty close scores. Should likely be used in production a lot, and more often soon.
Claude Sonnet 4.5 (Thinking 32K) is right behind the other two, with an astonishingly low $0.76 a task, lower than Grok 4 (Thinking) by a factor of 3. This should be used even more frequently in production as a strong default AI.
Fresh pull of the rankings today, here are the top 20 as of now:
| AI System | Organization | System Type | ARC-AGI-1 | ARC-AGI-2 | Cost/Task |
| Human Panel | Human | N/A | 98.00% | 100.00% | $17.00 |
| J. Berman (2025) | Bespoke | CoT + Synthesis | 79.60% | 29.40% | $30.40 |
| E. Pang (2025) | Bespoke | CoT + Synthesis | 77.10% | 26.00% | $3.97 |
| GPT-5 Pro | OpenAI | CoT | 70.20% | 18.30% | $7.14 |
| Grok 4 (Thinking) | xAI | CoT | 66.70% | 16.00% | $2.17 |
| Claude Sonnet 4.5 (Thinking 32K) | Anthropic | CoT | 63.70% | 13.60% | $0.76 |
| GPT-5 (High) | OpenAI | CoT | 65.70% | 9.90% | $0.73 |
| Claude Opus 4 (Thinking 16K) | Anthropic | CoT | 35.70% | 8.60% | $1.93 |
| GPT-5 (Medium) | OpenAI | CoT | 56.20% | 7.50% | $0.45 |
| Claude Sonnet 4.5 (Thinking 8K) | Anthropic | CoT | 46.50% | 6.90% | $0.24 |
| Claude Sonnet 4.5 (Thinking 16K) | Anthropic | CoT | 48.30% | 6.90% | $0.35 |
| o3 (High) | OpenAI | CoT | 60.80% | 6.50% | $0.83 |
| Tiny Recursion Model (TRM) | Bespoke | N/A | 40.00% | 6.30% | $2.10 |
| o4-mini (High) | OpenAI | CoT | 58.70% | 6.10% | $0.86 |
| Claude Sonnet 4 (Thinking 16K) | Anthropic | CoT | 40.00% | 5.90% | $0.49 |
| Claude Sonnet 4.5 (Thinking 1K) | Anthropic | CoT | 31.00% | 5.80% | $0.14 |
| Grok 4 (Fast Reasoning) | xAI | CoT | 48.50% | 5.30% | $0.06 |
| o3-Pro (High) | OpenAI | CoT + Synthesis | 59.30% | 4.90% | $7.55 |
| Gemini 2.5 Pro (Thinking 32K) | CoT | 37.00% | 4.90% | $0.76 | |
| Claude Opus 4 (Thinking 8K) | Anthropic | CoT | 30.70% | 4.50% | $1.16 |
View the entire leaderboard here at ARCprize.
Sep 18, 2025 AI Leaderboard Rankings
Table recreated courtesy of ARC Prize, a nonprofit.
This table shows the latest rankings following ARC 1 and 2 tests.
| Rank | AI System | Organization | System Type | ARC-AGI-1 | ARC-AGI-2 |
| 1 | Human Panel | Human | N/A | 98.00% | 100.00% |
| 2 | J. Berman (2025) | Bespoke | CoT + Synthesis | 79.60% | 29.40% |
| 3 | E. Pang (2025) | Bespoke | CoT + Synthesis | 77.10% | 26.00% |
| 4 | Grok 4 (Thinking) | xAI | CoT | 66.70% | 16.00% |
| 5 | GPT-5 (High) | OpenAI | CoT | 65.70% | 9.90% |
| 6 | Claude Opus 4 (Thinking 16K) | Anthropic | CoT | 35.70% | 8.60% |
| 7 | GPT-5 (Medium) | OpenAI | CoT | 56.20% | 7.50% |
| 8 | o3 (High) | OpenAI | CoT | 60.80% | 6.50% |
| 9 | o4-mini (High) | OpenAI | CoT | 58.70% | 6.10% |
| 10 | Claude Sonnet 4 (Thinking 16K) | Anthropic | CoT | 40.00% | 5.90% |
| 11 | o3-Pro (High) | OpenAI | CoT + Synthesis | 59.30% | 4.90% |
| 12 | Gemini 2.5 Pro (Thinking 32K) | CoT | 37.00% | 4.90% | |
| 13 | Claude Opus 4 (Thinking 8K) | Anthropic | CoT | 30.70% | 4.50% |
| 14 | GPT-5 Mini (High) | OpenAI | CoT | 54.30% | 4.40% |
| 15 | Gemini 2.5 Pro (Thinking 16K) | CoT | 41.00% | 4.00% | |
| 16 | GPT-5 Mini (Medium) | OpenAI | CoT | 37.30% | 4.00% |
| 17 | o3-preview (Low)* | OpenAI | CoT + Synthesis | 75.70% | 4.00% |
| 18 | Gemini 2.5 Pro (Preview) | CoT | 33.00% | 3.80% | |
| 19 | Gemini 2.5 Pro (Preview, Thinking 1K) | CoT | 31.30% | 3.40% | |
| 20 | o3-mini (High) | OpenAI | CoT | 34.50% | 3.00% |
See full table here: ARC Leaderboard
How ARC-AGI-1 Works
“ARC-AGI-1 consists of 800 puzzle-like tasks, designed as grid-based visual reasoning problems. These tasks, trivial for humans but challenging for machines, typically provide only a small number of example input-output pairs (usually around three). This requires the test taker (human or AI) to deduce underlying rules through abstraction, inference, and prior knowledge rather than brute-force or extensive training.”
ARC-AGI-2 Explained:
Here’s a direct quote:
“ARC-AGI-1 was created in 2019 (before LLMs even existed). It endured 5 years of global competitions, over 50,000x of AI scaling, and saw little progress until late 2024 with test-time adaptation methods pioneered by ARC Prize 2024 and OpenAI.
ARC-AGI-2 – the next iteration of the benchmark – is designed to stress test the efficiency and capability of state-of-the-art AI reasoning systems, provide useful signal towards AGI, and re-inspire researchers to work on new ideas.
Pure LLMs score 0%, AI reasoning systems score only single-digit percentages, yet extensive testing shows that humans can solve every task.
Can you create a system that can reach 85% accuracy?”
July 10, 2025 AI Leaderboard Rankings
As of July 10, 2025 Grok 4 is the best AI model, according to ARC Prize’s ARC-AGI Leadersboard.
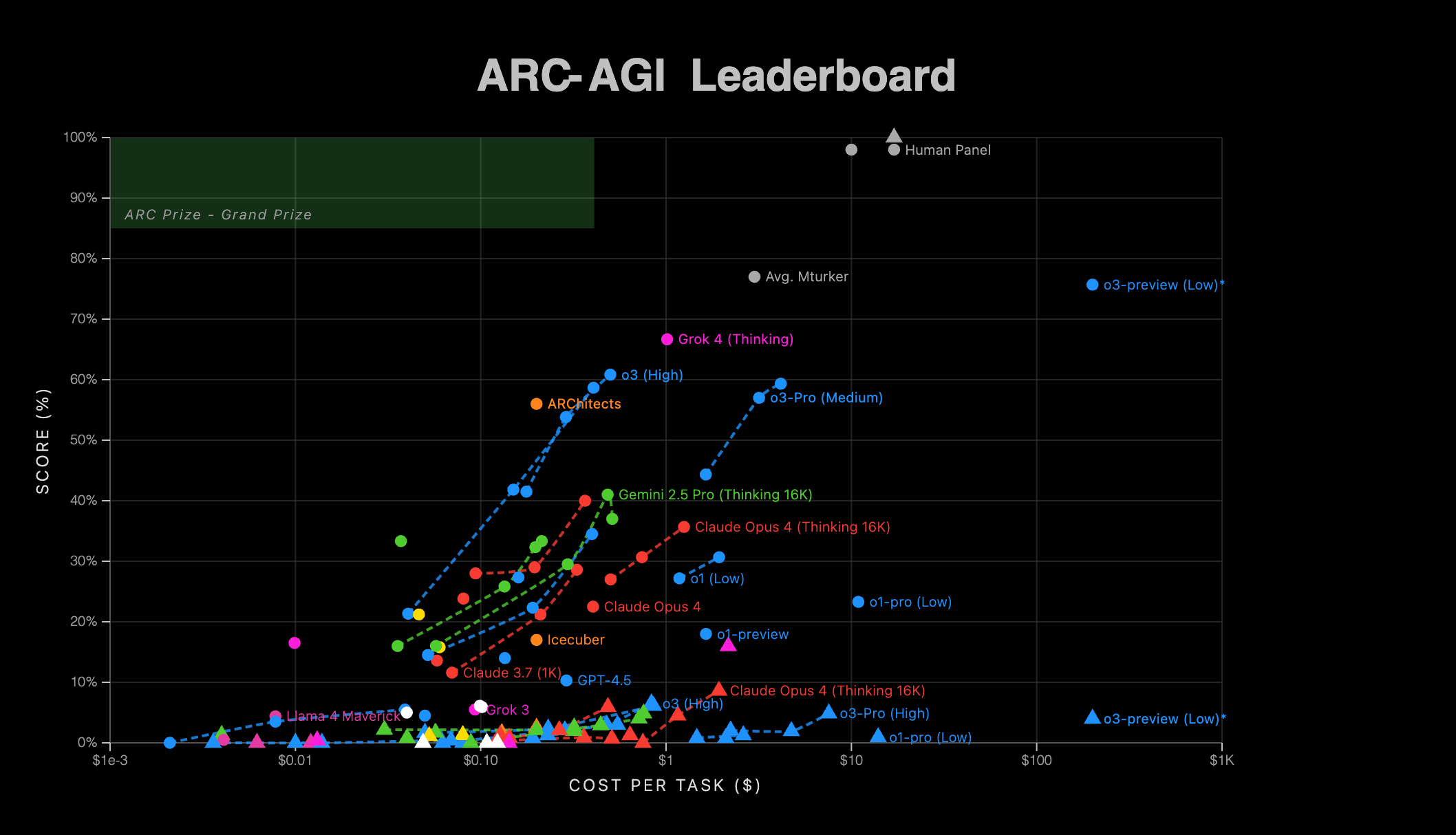
According to their X announcement:
“Grok 4 (Thinking) achieves new SOTA on ARC-AGI-2 with 15.9% This nearly doubles the previous commercial SOTA and tops the current Kaggle competition SOTA.”
-ARC on X
View the full ARC-AGI Leaderboard page for real-time updates.
According to their team:
“ARC-AGI has evolved from its first version (ARC-AGI-1) which measured basic fluid intelligence, to ARC-AGI-2 which challenges systems to demonstrate both high adaptability and high efficiency.
The scatter plot above visualizes the critical relationship between cost-per-task and performance – a key measure of intelligence efficiency. True intelligence isn’t just about solving problems, but solving them efficiently with minimal resources.”
Other Leaderboards
Kearney Leaderboard: Out of Date
We don’t recommend referencing this one by Kearny, as it mentions o1 as an “up and coming” model, so it’s already out of date.



Leave a Reply